
Shipping 50% more defects and calling it AI adoption
A rise in Change Failure Rate tells us more about AI adoption than any productivity benchmark

👋 Hi, I’m Thomas. Welcome to a new edition of Beyond Runtime, where I dive into the messy, fascinating world of distributed systems, debugging, AI, and system design. All through the lens of a CTO with 20+ years in the backend trenches.
QUOTE OF THE WEEK:
“Vibe coding is just undisciplined prompt iteration masquerading as engineering. Spray-and-pray loops where you chase outputs that feel right while ignoring the underlying system. It treats code as an opaque byproduct instead of a first-class artifact, which doesn’t scale past toy prototypes” - Karthik Ramgopal, distinguished engineer at LinkedIn.
A recent DX report on AI-assisted engineering confirms what many engineering teams have been quietly noticing: adoption is up, but quality continues to be inconsistent. This insight is particularly interesting to me:
While some organizations are seeing clear improvement to quality as AI usage increases, others are seeing serious degradation, with many swinging significantly.
Change Failure Rate* is of particular interest, with some companies increasing this value by almost 2%. Given an industry benchmark of 4%, this indicates that some companies are shipping as many as 50% more defects than before.
* Change Failure Rate: the percentage of changes that result in degraded performance that must be immediately fixed
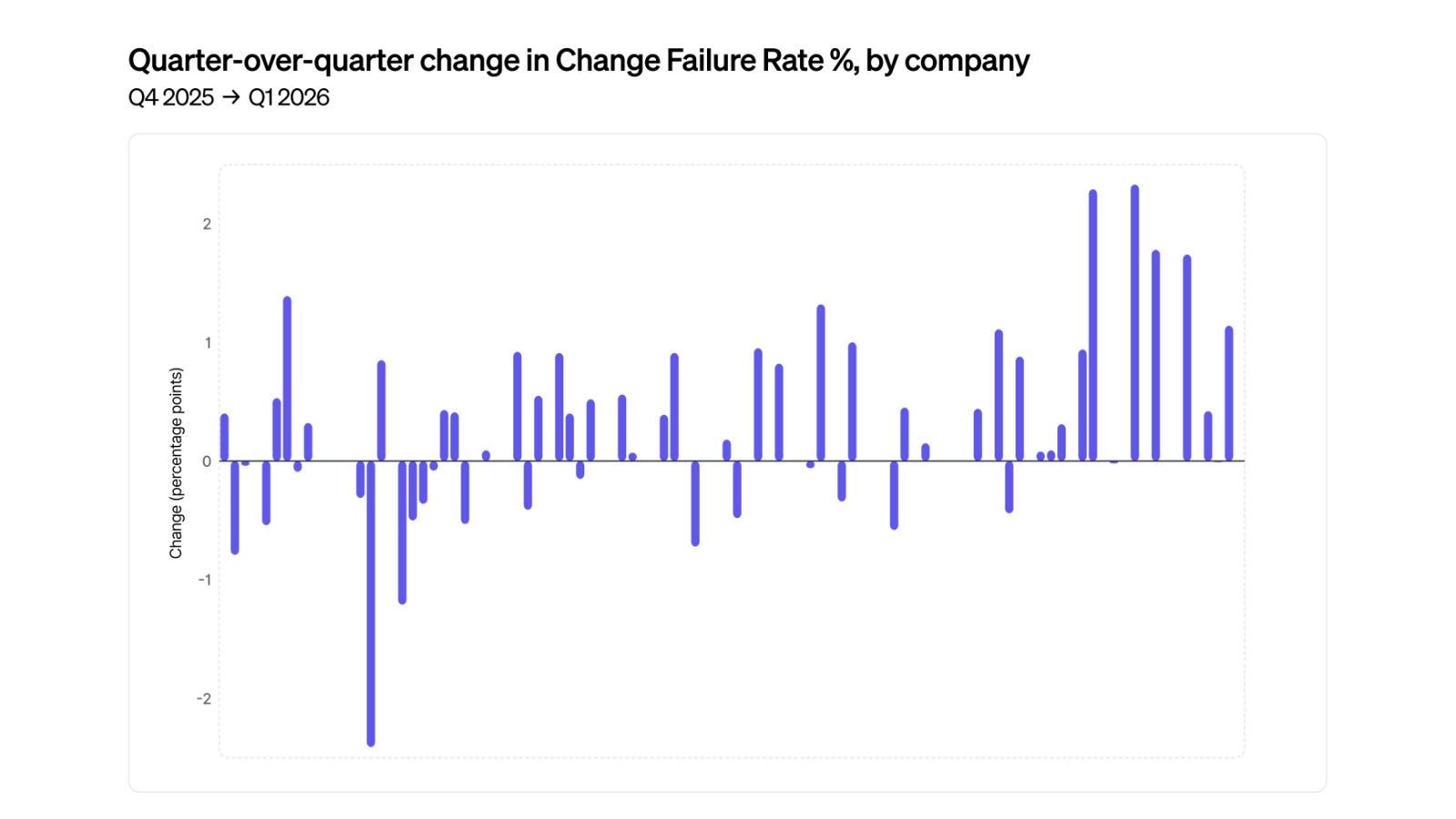
I’ve spoken at length about the connection between AI output quality and data, and this is yet another clue of this problem.
But it’s easy to miss because of how AI agents fail: bad data produces plausible output. For example, the model doesn’t know it’s missing the correlation between the frontend event and the backend trace. It reasons over what it has, makes the most statistically likely inference about what the gap contains, and presents the result as a finding. The output looks reasonable right up until it fails in prod.
If the data is noisy → the agent confabulates confidently
If the data is too broad → the agent gets lost
If the metadata is inconsistent → the agent can’t reconcile
If the context is unbounded → the agent lacks the developer’s intuition to zoom inThis is the mechanism behind those Change Failure Rate numbers. Teams are feeding coding agents data from tools originally built for human operators: sampled, siloed, missing critical elements, not automatically correlated or deduplicated. The agents do what agents do: reason over what they have and produce a confident answer. The answer just happens to be wrong.
The mental model that needs to change
The shift required is straightforward to state and harder to execute: stop asking what data your dashboards need. Start asking what a senior developer would need to sit down and debug a specific bug from scratch, quickly.
That developer doesn’t want aggregate system health data or sampled traces across all sessions. They want five specific things:
(1) The exact session. Not all sessions ever recorded, or a sampled subset. The actual sequence of events for this specific bug. General system health monitoring and targeted debugging are different questions. They require different data.
(2) Auto-correlation across the stack. Frontend events, backend traces, and everything in between automatically pre-correlated, without having to manually reconciling timestamps across three different tools.
(3) Full request and response content at every service boundary. Most tools only collect browser-side payloads. Coding agents reasoning over incomplete request chains will fill the gaps with inference. Those inferences are where the plausible-but-wrong fixes come from.
(4) Clean, consistent naming. An agent that encounters three different identifiers for the same service doesn’t flag that inconsistency or treats them as the same service.
(5) Deduplicated issues. Ten alerts for the same problem give an agent ten opportunities to treat a single failure as multiple distinct issues (together with an opportunity to waste tokens).
None of this is what traditional observability tools were built to provide because they were built to answer the question “is the system healthy?”.
The question that coding agents need to answer is “exactly what happened, where in the code, and how do you fix it?”.
Those are different questions. They require different data.
Final thoughts
The reason quality continues to be inconsistent is because the failure mode is subtle. An agent working from incomplete, poorly correlated data still returns a PR which oftentimes passes CI and looks syntactically correct. Nobody notices the defect it introduces and it shows up in your Change Failure Rate only two weeks later.
The sooner the distinction between dashboard data and agent data becomes a first-class engineering concern (i.e. we design for coding agent needs and not retrofit for them) the sooner coding agents will actually deliver on what everyone expects them to do.
💜 This newsletter is sponsored by Multiplayer.app, the debugging agent for developers.
📚 Interesting Articles & Resources
AI-assisted engineering: Q1 impact report - DX
Unsurprisingly the use of AI continues to grow and now 92.7% of developers are using AI coding tools at least monthly. Also unsurprisingly the impact on quality continues to be varied and volatile.
AI Slop is Killing Online Communities - Robin Moffatt
Advice for anyone posting on the internet: “is it actually adding to the cumulative understanding of the community, or is it just an LLM auto-completing its way through text that you can’t be arsed to write and I can’t be arsed to read?”