
PR reviews can't be the only quality gate for AI-generated code
Engineering teams need to rethink software quality verification from the ground up.

👋 Hi, I’m Thomas. Welcome to a new edition of Beyond Runtime, where I dive into the messy, fascinating world of distributed systems, debugging, AI, and system design. All through the lens of a CTO with 20+ years in the backend trenches.
QUOTE OF THE WEEK:
“[…] we’ve accelerated code generation without evolving our verification and ownership models. Teams are producing more than they can reason about. Until we invest in better abstractions, testing strategies, and system boundaries, this gap will continue to widen.” - Mallika Rao, senior software engineering manager at Zocdoc
This 👇 is a screenshot of a PR for an AI-generated port from one build system to another. A rare, large refactor that can touch hundreds of files at once. I posted it on LinkedIn as an example of a symptom pointing to a deeper problem, which I explored in my article “PR reviews were already broken. AI made it worse”.
To my surprise, the post got 60+ comments in under a day.
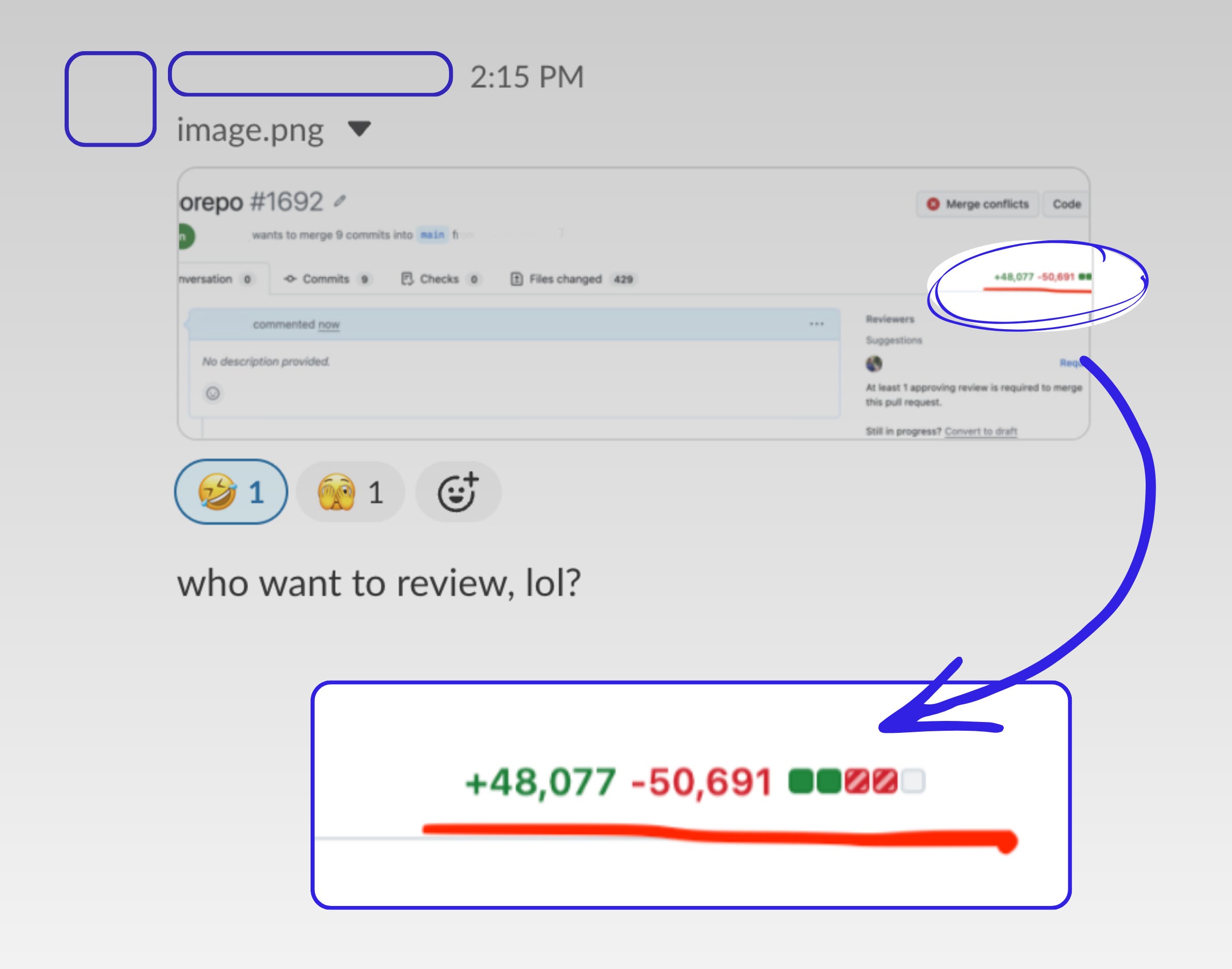
The comments fell into three buckets: a visceral reaction to the image itself (”just reject it,” “shouldn’t exist”), engagement with the PR review problem but not its underlying causes, and a small handful who actually wrestled with my argument about the need to evolve how we verify software quality.
What struck me was how quickly the conversation jumped to PR best practices. Almost nobody stopped to question whether the review process itself still makes sense as a primary quality gate.
It’s like all these engineers walked past a building on fire to debate the exit sign.
After all, the PR review model was already struggling when humans wrote code at human speed. In many engineering orgs, it’s not uncommon for PRs to sit unreviewed for days. Reviewers sometimes skim 500-line diffs and move on.
AI coding agents just poured fuel on top of it.
Reviewing PRs has never been harder
One of the main reasons why reviewing PRs was already hard is because reviewing code you didn’t write has always been harder than writing it yourself.
When you write the code, you carry the context: the trade-offs you considered, the approaches you rejected, the reason this particular solution made sense for this codebase at this moment. When you review someone else’s code, you’re reconstructing all of that from the diff alone.
But with coding agents, teams have to contend with a larger volume of PRs, and lower average quality.
There’s undoubtedly some genuinely useful fix suggestions buried in the pile of AI-generated PRs. But the phenomenon of PR slop is very real, and it’s showing up everywhere. GitHub’s Octoverse 2025 report documents what open source maintainers are now calling “AI slop”: high-volume, low-quality, often inaccurate contributions that don’t add value to a project.
It’s also a pattern you see with every bug detection tool that bolted AI on top. The CEO of a well-known error monitoring tool even admitted in a post: “in practice you end up with low quality PRs that are annoying to fix up.”
The underlying reason is that most tools weren’t designed for AI from the ground up. They were built to surface problems for humans to investigate, and, when the AI layer was added on top, none of the underlying infrastructure (how they gather data, group issues, etc) was evolved to better serve the needs of AI agents.
The result is agents that have to reason over incomplete, poorly correlated and grouped data, producing fixes that are plausible-looking but miss the actual root cause.
Teams were already struggling to stay on top of human-written, high-quality PRs. They are now getting overwhelmed by high-volume, low-quality, AI-generated PRs.
Emerging solutions
Many approaches have emerged to address the PR review problem, each tackling it from a slightly different angle. Here’s some examples:
Spec-driven development focuses on giving agents context even before a single line of code is written. If the agent works from a detailed, well-reasoned specification, the output is more predictable and the reviewer has something to check the code against.
Multi-agent competition takes a different approach: assign the same task to multiple agents simultaneously, let them produce diverging solutions, and pick the best outcome.
Better data infrastructure for agents addresses the data fed into agents: when agents can reason with high-quality data (e.g. unsampled, full-stack, pre-correlated, deduplicated context), the quality of what comes out the other side changes significantly.
Automated verification layers (expanded test coverage, CI checks, static analysis) catch what reviews used to catch, earlier and faster, without requiring a human to be in the loop for every change.
None of these approaches are mutually exclusive.
A team doing spec-driven development still benefits from better agent data. A team with strong automated verification could still explore multi-agent competition on complex problems.
That’s the insight worth sitting with: there’s no single tool that fixes the PR review problem. What’s actually emerging is that we need a wholesale rethink of how software gets built.
The Swiss cheese model
A complex problem rarely has a simple solution. And complex systems rarely fail because of a single thing that went wrong. How we verify software quality is a complex problem and there is no single tool, process, or methodology that will magically solve it.
The Swiss cheese model might be the most honest framework we have for thinking about it. Imagine several slices of Swiss cheese stacked on top of each other. Each slice represents a defensive layer: a process, a check, a safeguard. Each slice has holes, representing the weaknesses and gaps in that layer. No single slice is perfect. But as long as the holes don’t align across all the slices simultaneously, nothing gets through. Stack enough imperfect layers and you get a system that’s more reliable than any individual component.
Applied to software development: spec-driven development catches misaligned intent before a line is written. High-quality data grounds the agent’s reasoning in something trustworthy. Automated verification catches what slips through anyway. No single layer is airtight. But together, they don’t need to be.
Or maybe we’ll end up with a completely different approach, one that nobody has fully articulated yet.
What’s certain is that the way we verify software quality needs to evolve at the same pace as the way we generate it.
💜 This newsletter is sponsored by Multiplayer.app, the debugging agent for developers.
📚 Interesting Articles & Resources
AI coding made us faster. Why did incidents increase? - Parthiban Rajasekaran
The DORA report confirmed that teams with significantly higher AI adoption also showed a higher change failure rate. Rajasekaran makes a strong case for spec-first prompting and classifying AI-generated PRs by risk, both good additions to the quality stack.
Where I’d push back: the claim that ‘every model works on the code it is shown and has no awareness of the broader system’ is inaccurate. Feed the agent full-stack, pre-correlated, unsampled runtime data and its awareness of the broader system changes materially. The non-determinism doesn’t disappear, but it gets grounded in what actually happened, which is a very different starting point than static code alone.